
近日,北京理工大学信息与电子学院博士生张宇翔、张蒙蒙副研究员、李伟教授、陶然教授,提出了一种“语言感知域泛化网络”,研究结果以《Language-Aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification》为题,发表于顶级期刊电气和电子工程师协会地学与遥感汇刊IEEE Transactions on Geoscience and Remote Sensing, (影响因子IF: 8.125)。
在目前无论是领域自适应还是领域泛化,所有的用于遥感场景的方法,均缺乏利用包含遥感地物先验知识的语言模态。如图1所示,在计算机视觉领域,图像和文本的大规模匹配训练已表明有助于视觉表征的学习。然而,在遥感场景中从未使用过文本信息,严重缺乏先验知识的嵌入。

图1缺乏遥感地物先验知识
对此,本工作提出了提出语言感知域泛化网络(LDGnet),其模型框架如图2所示。该方法将文本提供的先验知识作为域不变信息,构建image-text pairs并提取嵌入特征,通过视觉-语言对齐的方式,实现领域泛化。LDGnet是首个多模态学习的高光谱图像分类框架,实现视觉语言多模态表征,构建遥感先验嵌入新范式。

图2语言感知域泛化模型框架图
首先,在训练阶段设计Image encoder提取视觉特征,Text encoder提取粗粒度和细粒度的语言特征,形成语义空间。将语义空间视为域间共享空间,通过视觉-语言对齐的方式将数据投影至语义空间,逐类别缩小视觉特征与语言特征之间的差异,最终输出视觉模态分类预测概率。其中,根据源域场景中地物的先验知识,对各个地物类别分配粗粒度和细粒度文本描述。如图3所示实心五角星,将 A hyperspectral image of <class name> 作为模板,以完形填空的方式构建各个类别的粗粒度文本描述。至于细粒度文本,结合先验知识从颜色、形状、分布、邻接关系等方面进行人工描述,例如 The grass stressed is pale green,The trees beside road 和 The road appear as elongated strip shape。每个类别设定两个细粒度文本,如图3所示的空心五角星。在测试阶段,利用Image encoder和classifier head预测来自目标场景。
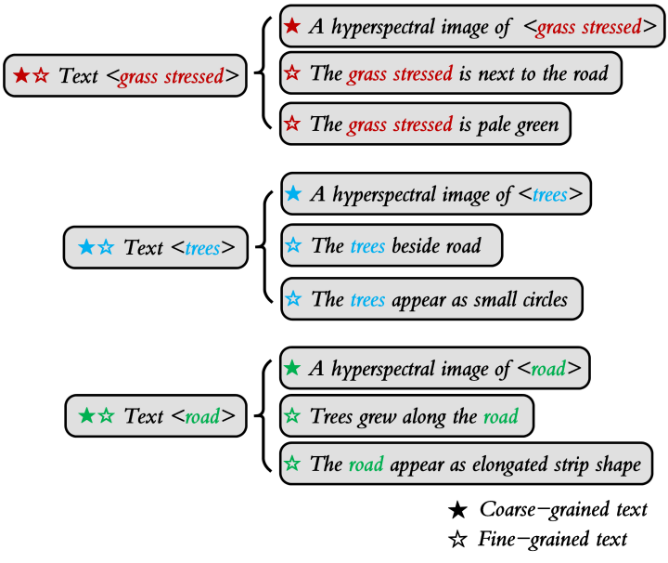
图3 三个类别的粗粒度和细粒度文本示例
在两个高光谱图像数据集和一个多光谱数据集上的大量实验证明了该方法与现有技术相比的优越性,原始空间和语义空间中的特征可分性如图4所示,属于同一类的特征的聚合得到了很大的改善。如图5所示,LDGnet与领域泛化方法在目标场景Houston2018的预测分类图对比。
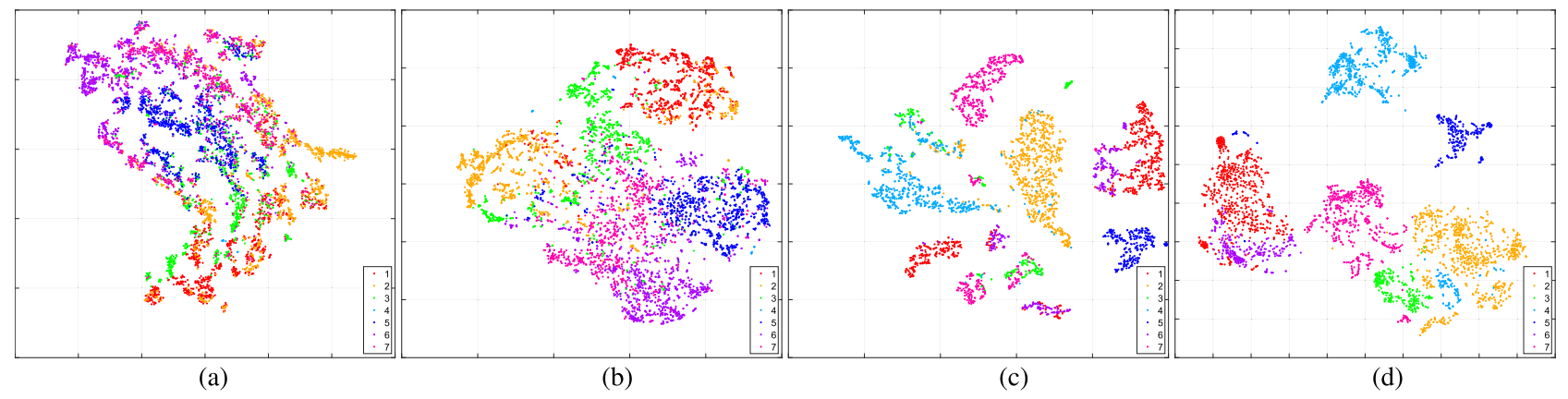
图4可分性分析,其中(a)和(b)是Houston 2018年的数据,(c)和(d)是Pavia Center数据,原始特征→LDGnet特征(a→b & c→d)

(a) 传统方法 (73.64%) (b)所提方法 (80.08%)
图5目标场景Houston2018预测分类图
论文地址:https://ieeexplore.ieee.org/document/10005113
开源代码:https://github.com/YuxiangZhang-BIT/IEEE_TGRS_LDGnet